Pengantar
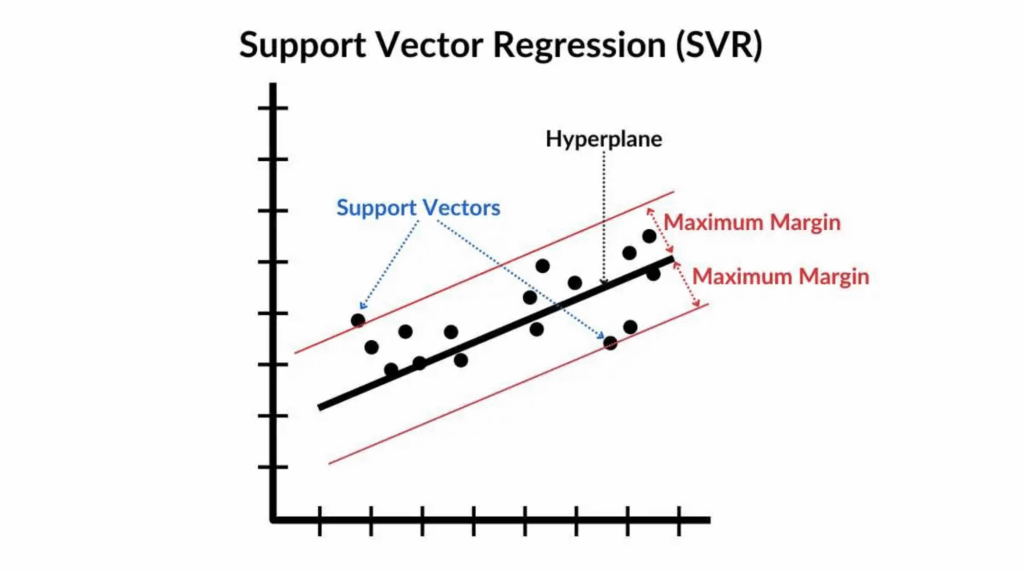
Support Vector Regression (SVR) adalah adaptasi dari algoritma Support Vector Machine (SVM) untuk regresi.
Berbeda dari regresi linear biasa yang berusaha meminimalkan error antara prediksi dan target, SVR berusaha menyesuaikan model sehingga semua data berada dalam toleransi error tertentu (disebut ( \epsilon )-tube) sambil menjaga margin maksimal.
Formulasi Matematis
Diberikan dataset \( { (x_i, y_i) }_{i=1}^n \), tujuan SVR adalah mencari fungsi:
\[
f(x) = w^T x + b
\]
dengan tujuan:
- Semua prediksi \( f(x_i) \) berada dalam jarak \( \epsilon \) dari nilai aktual \( y_i \).
- Menjaga agar \( w \) sekecil mungkin (menghindari overfitting).
Fungsi Loss (( \epsilon )-Insensitive Loss)
Loss function yang digunakan:
\[
L_\epsilon (y, f(x)) =
\begin{cases}
0, & \text{jika } |y – f(x)| \leq \epsilon \
|y – f(x)| – \epsilon, & \text{lainnya}
\end{cases}
\]
Artinya, error di bawah \( \epsilon \) diabaikan.
Optimasi
Persoalan optimasi primal:
Minimalkan:
\[
\frac{1}{2} |w|^2 + C \sum_{i=1}^n (\xi_i + \xi_i^*)
\]
dengan syarat:
\[
\begin{aligned}
y_i – w^T x_i – b &\leq \epsilon + \xi_i \
w^T x_i + b – y_i &\leq \epsilon + \xi_i^* \
\xi_i, \xi_i^* &\geq 0
\end{aligned}
\]
di mana:
- \( \xi_i, \xi_i^* \) adalah slack variables untuk pelanggaran batas ( \epsilon ).
- \( C \) adalah parameter regularisasi untuk trade-off antara model sederhana dan toleransi error.
Kernel Trick
Untuk masalah non-linear, SVR dapat menggunakan fungsi kernel \( K(x_i, x_j) \) untuk memetakan input ke ruang berdimensi lebih tinggi:
Contoh kernel umum:
- Linear: \( K(x_i, x_j) = x_i^T x_j \)
- Polynomial: \( K(x_i, x_j) = (\gamma x_i^T x_j + r)^d \)
- RBF (Gaussian): \( K(x_i, x_j) = \exp(-\gamma |x_i – x_j|^2) \)
Parameter Penting SVR
- \( C \): Kontrol penalti terhadap error.
- \( \epsilon \): Lebar zona bebas error.
- \( \gamma \) (untuk kernel RBF): Kontrol pengaruh satu data point.
Contoh Latihan
Contoh 1: SVR Linear
Diberikan data:
| x | y |
|---|---|
| 1 | 2 |
| 2 | 2.8 |
| 3 | 3.5 |
| 4 | 5 |
| 5 | 5.1 |
Dengan \( \epsilon = 0.2 \), gambarkan kira-kira posisi \( \epsilon \)-tube yang mencakup data.
Hint:
- Cari regresi linear sederhana \( f(x) = w^T x + b \).
- Pastikan semua data maksimal deviasi \( 0.2 \).
- Jika ada pelanggaran, tambahkan slack variable \( \xi_i \).
Penugasan
Penugasan 1: Implementasi SVR Linear
Buat program Python sederhana menggunakan sklearn.svm.SVR untuk fitting data berikut:
| x | y |
|---|---|
| 0.5 | 1.4 |
| 1.0 | 1.9 |
| 1.5 | 2.5 |
| 2.0 | 3.0 |
| 2.5 | 3.7 |
Dengan ketentuan:
- Gunakan kernel linear (
kernel='linear'). - Set parameter \( \epsilon = 0.1 \) dan \( C = 1 \).
- Plot hasil regresi dan \( \epsilon \)-tube.
Penugasan 2: Eksperimen Parameter
Ubah-ubah nilai \( \epsilon \) dan \( C \) pada model di Penugasan 1.
Jawab:
- Bagaimana pengaruh perubahan \( \epsilon \) terhadap fit model?
- Bagaimana pengaruh perubahan \( C \) terhadap jumlah data yang melanggar \( \epsilon \)?
Penugasan 3: SVR dengan Dataset Open Source
Gunakan dataset California Housing dari sklearn.datasets untuk membangun model Support Vector Regression (SVR).
Langkah-langkah:
- Load dataset menggunakan
fetch_california_housing. - Pilih satu fitur saja, misalnya
MedInc(Median Income). - Lakukan split data menjadi data training dan testing (80:20).
- Fit model SVR dengan:
- Kernel RBF (
kernel='rbf') - Kernel Polynomial
- Kernel RBF (
- Plot hasil prediksi versus data aktual pada data testing.
Sumber Data:
- 1. California Housing Dataset
Deskripsi: Harga rumah di California berdasarkan data sensus 1990.
Link:
Scikit-Learn: California Housing
2. Boston Housing Dataset (Note: deprecated, tapi masih bagus untuk latihan offline)
Deskripsi: Harga rumah di Boston berdasarkan berbagai faktor seperti tingkat kriminalitas, aksesibilitas transportasi, dll.
Link:
Kaggle: Boston Housing Dataset
3. Concrete Compressive Strength Dataset
Deskripsi: Prediksi kekuatan beton berdasarkan bahan-bahan seperti semen, air, pasir, dan lain-lain.
Link:
UCI Machine Learning Repository: Concrete Dataset
4. Energy Efficiency Dataset
Deskripsi: Prediksi penggunaan energi dalam bangunan berdasarkan karakteristik desain seperti luas dinding, atap, dan orientasi.
Link:
UCI Machine Learning Repository: Energy Efficiency
5. Airfoil Self-Noise Dataset
Deskripsi: Prediksi tingkat kebisingan airfoil berdasarkan kecepatan angin, frekuensi, sudut serang, dll.
Link:
UCI Machine Learning Repository: Airfoil Self-Noise
6. Bike Sharing Dataset
Deskripsi: Prediksi jumlah sepeda yang disewa berdasarkan cuaca, hari dalam seminggu, musim, dll.
Link:
UCI Machine Learning Repository: Bike Sharing
7. Wine Quality Dataset
Deskripsi: Prediksi kualitas wine berdasarkan karakteristik kimia seperti kadar alkohol, pH, gula, dan lain-lain.
Link:
UCI Machine Learning Repository: Wine Quality
Dataset ini merupakan data publik dari “1990 California Census”.
Pertanyaan untuk dijawab:
- Bagaimana performa SVR terhadap data ini?
- Coba ubah nilai \( C \) dan \( \gamma \), apa pengaruhnya terhadap hasil regresi?
- Apa perbedaan Regresi Linier dengan model SVR ini berdasarkan pengalaman anda?
Referensi
- Vapnik, V. (1995). The Nature of Statistical Learning Theory.
- Smola, A., & Schölkopf, B. (2004). A tutorial on support vector regression.
Dokumen dibuat tanggal 27 April 2025
#artificial intelligence #belajar data #data #data mining #data science #machine learning #support vector regression #svm #svr